ServiceNow development is high stakes and slow to get right. A developer staring at a broken form, a slow Business Rule, or a vague build me a utility request pays three recurring taxes, and a generic AI assistant makes every one of them worse.
The first is the diagnosis tax: working out what the screenshot is even showing, which table, which error, which form context, before any real work can start. The second is the correctness tax. ServiceNow has strong opinions, Script Includes versus GlideAjax versus Scripted REST, GlideRecord performance, the ACL surface, and a generic assistant will happily hallucinate a plausible but wrong API. Here a wrong answer ships to production. The third is the proof tax. Even a correct answer is just words until it compiles and runs on the instance, and the developer is still left to build and test it by hand.
Most AI co-pilots stop at confident prose. The hard and valuable part, grounding the answer in real documentation and proving it runs, is exactly what they skip. That gap is the product.
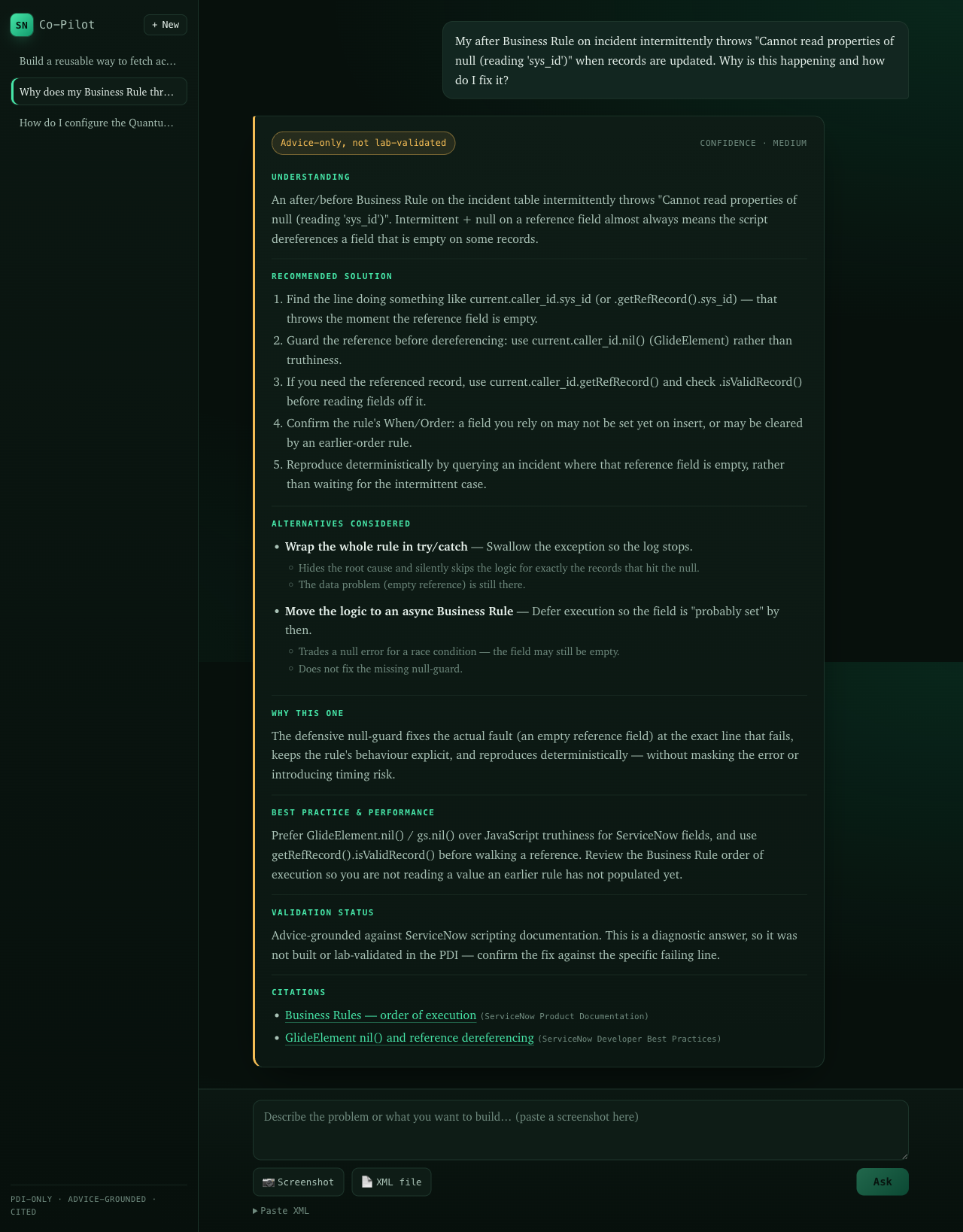
The clearest way to understand the product is its trust spectrum. The same interface renders three honestly different classes of answer, and it never pretends one is another. An answer is graded by how much I can actually stand behind it, not by how confident the prose sounds.
Built + lab validated
A buildable solution is actually built and smoke tested in a sandbox ServiceNow instance, a Personal Developer Instance, then exported as an Update Set the developer imports. Nothing is claimed validated unless it ran. This is the hero flow.
Diagnostic, advice only
Not everything is buildable. A why is this happening question is classified as diagnostic, grounded in retrieved docs and cited on every claim, and labelled advice only, not lab validated. Real advice, never dressed up as something that was tested.
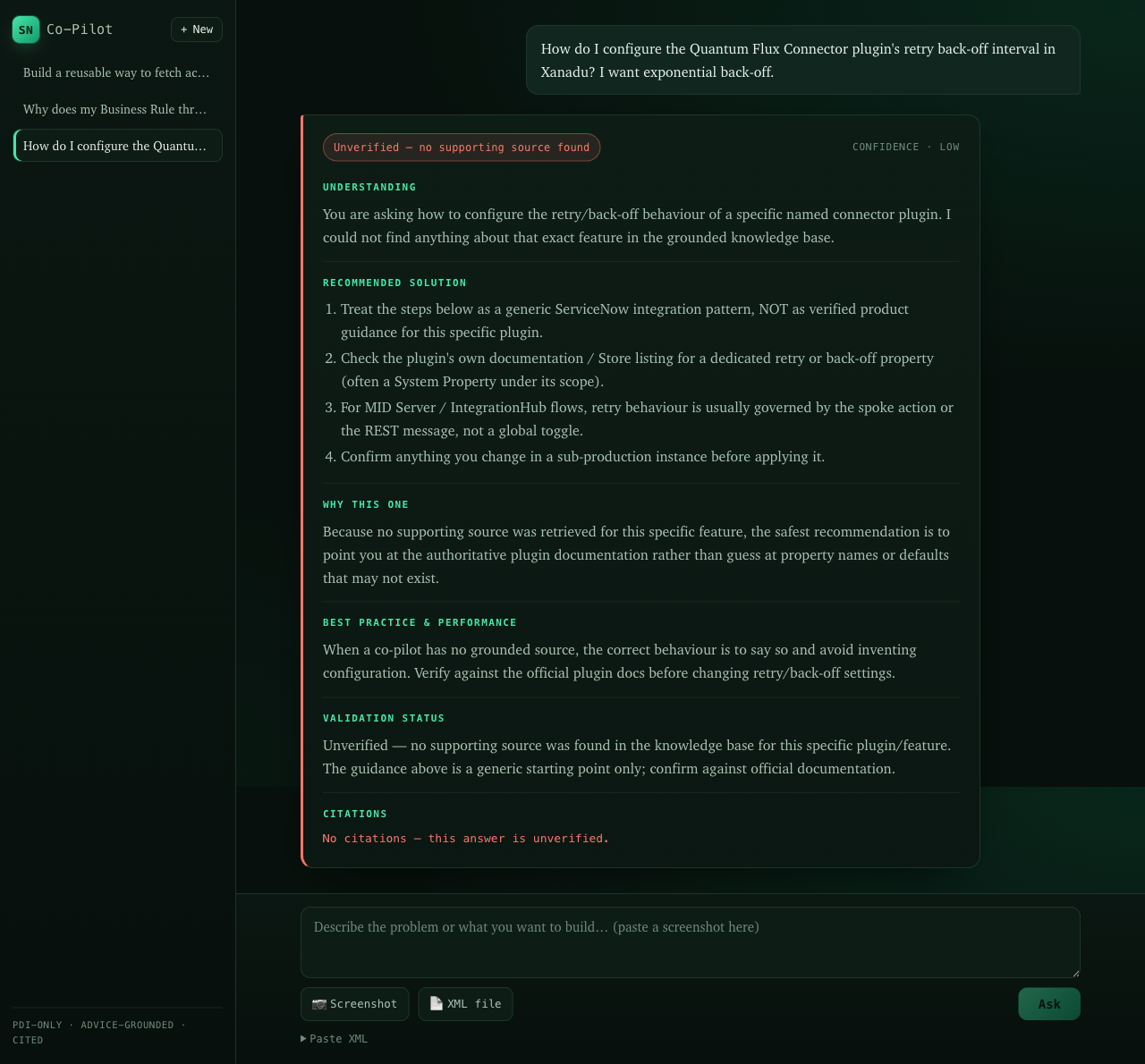
Unverified
Asked about something with no supporting source, the co-pilot admits it. It returns an unverified badge, low confidence, and zero citations, offers a generic starting point, and refuses to invent a property name or a citation.
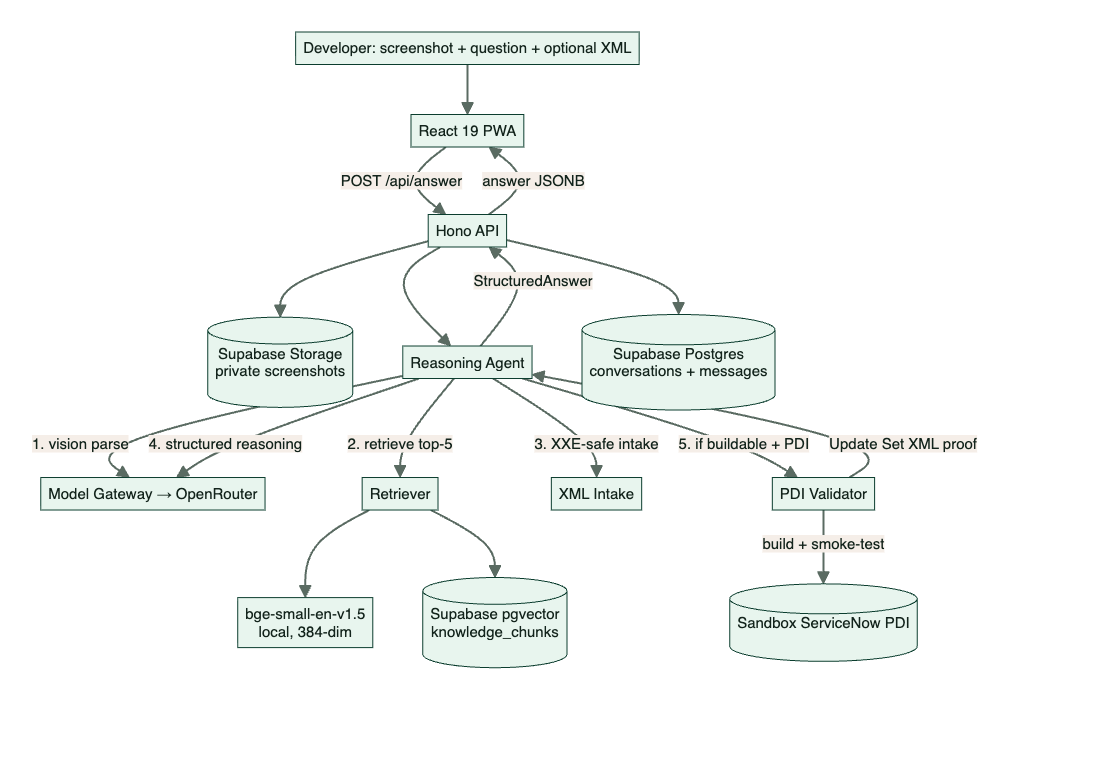
The whole system is shaped to make a wrong or unsafe answer structurally hard, not just discouraged. A developer pastes a screenshot, types a question, and optionally attaches a ServiceNow XML export. The request flows through a reasoning agent that parses the image, retrieves cited chunks, reasons into a strict contract, classifies the request, and only then, if it is buildable and a sandbox is configured, builds and proves it. The diagram below is not a description of the code, it is the set of decisions that make the trust model real.
Every screen below is captured from the running application. Together they walk the full path: from the composer a developer types into, through the source it reads, to the three honest answer tiers, the offline state, and the phone.
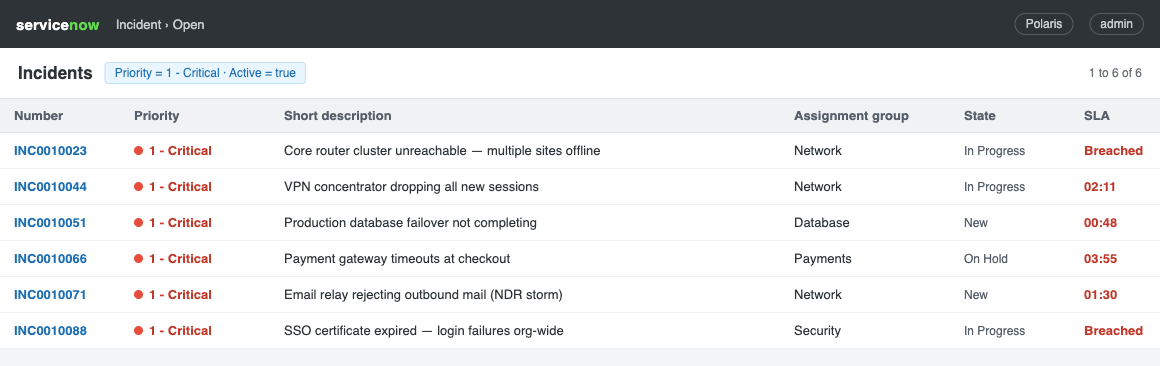
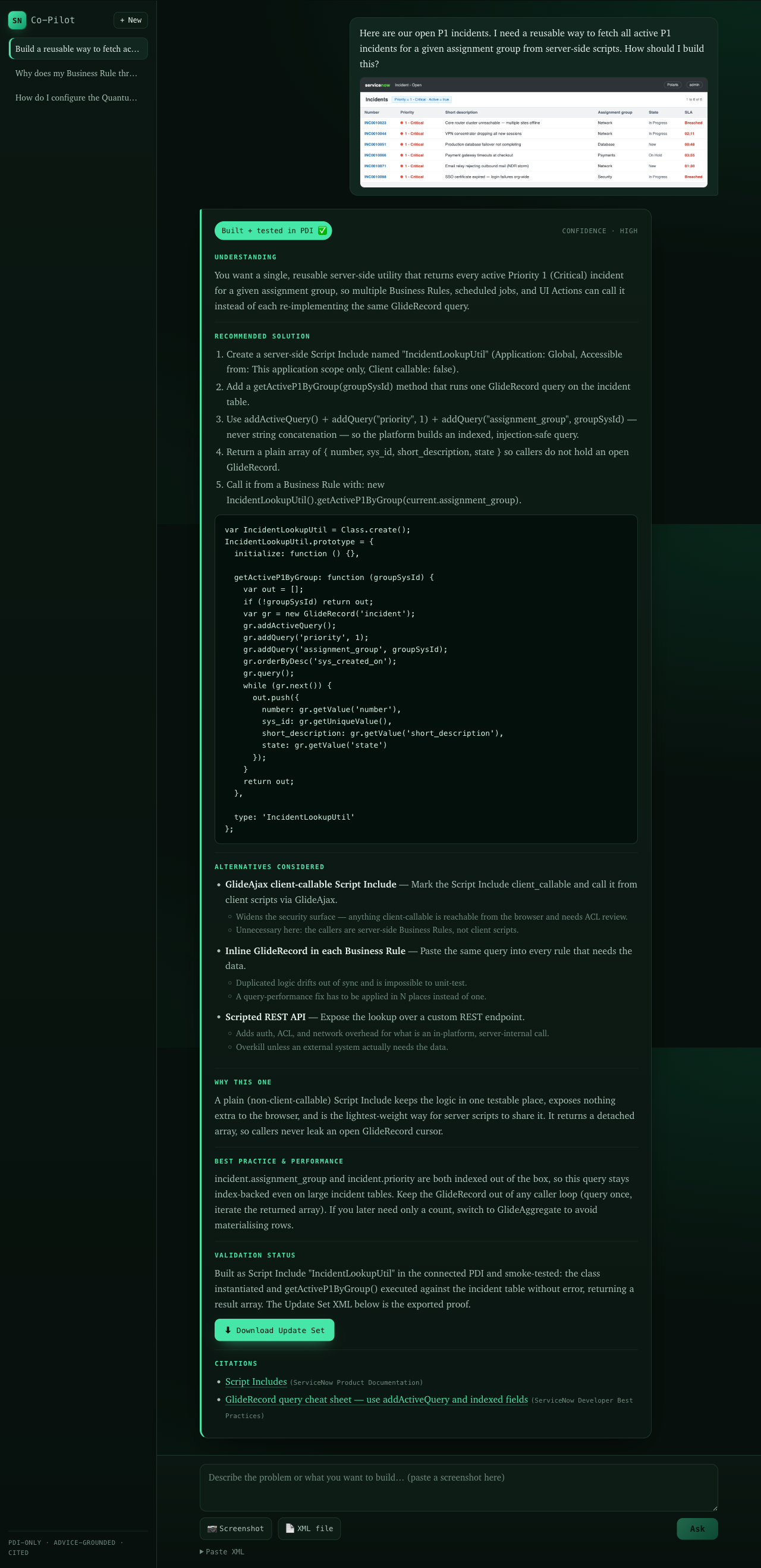

Screenshots are captured from the running application. The demo conversations are curated to show the full trust spectrum, and they render through the live persistence and UI path.
The product was delivered in seven sequenced phases, each test driven and merged behind passing checks: model gateway, then the knowledge layer, then the reasoning agent and XML intake, then the PDI validator, then persistence, then the web app and PWA, and finally the evaluation harness.
Quality is measured, not vibed. A golden set scores every answer on five weighted dimensions, completeness, citation or unverified, kind match, concept coverage, and groundedness, and two of them are hard guardrails: anti hallucination and groundedness. A model A/B benchmark holds retrieval constant and swaps only the model, so the cheapest one that clears the guardrails wins, and only free, vision capable models are ever in the running.
A later high effort code review pass found and fixed 10 issues, each with a regression test, from a conversation timestamp bug to a double decoded screenshot path. The result is a codebase where the safety critical behaviours are the most tested ones.
Safety is tested, not assumed. The PDI-only guard and the anti hallucination and groundedness behaviour each have dedicated tests, so a regression that let the model invent a citation, or let the validator touch a non PDI host, fails CI.
One language across the API, web and scripts, with Zod giving runtime and compile time safety. The Answer Contract is the spine of the whole app.
- Designed the trust model, the three honest answer tiers and the rule that the model never holds the pen on a citation, which was a product and safety design problem, not a prompt.
- Designed the knowledge layer: a local embedding pipeline and pgvector retrieval whose chunks become the citations the orchestrator attaches.
- Designed the reasoning agent and the strict Answer Contract that turns model output into a structured, validatable answer.
- Designed the PDI validator, the PDI-only safety guard, and the build then test then prove flow that degrades honestly to advice only.
- Designed persistence and the web PWA: schema decoupled answer storage, a private screenshot bucket, and an offline aware shell.
- Designed the evaluation harness: the golden set, the five weighted dimensions, and the guardrailed model A/B benchmark.
- Shipped it across seven phases and led the review and hardening pass that found and fixed 10 issues with regression tests.
Want the full walkthrough?
I am happy to demo ServiceNow Co-Pilot live and talk through the trust model, the architecture, and how I designed and shipped it end to end.