Job hunting is a part time job made of repetitive, low leverage work. You search the same boards every day and most of what you find is noise. You eyeball each posting and guess whether you are a fit. For anything promising, you rewrite your resume and a cold note from scratch. Then you lose track of what you applied to and what came back.
The judgment is the valuable part. The searching, the scoring, the rewriting, and the tracking are not. That is exactly the kind of grind an agent should own, while the person keeps the decisions.
So I built Job Agent to run the loop for you. You onboard once, and the agent works every day: it finds roles, scores each one 0 to 100 for fit with a reason, tailors a resume and outreach draft for the strong matches, tracks everything on a pipeline board, and emails you a short digest of what it found. You stay in control of who you actually apply to.
The run is a five step loop. Each step does one job and passes its state to the next, so the agent is predictable and every stage is testable on its own. Here is what happens once a day, framed as the product steps a job seeker actually cares about.
1 · Find and dedup
It gathers roles from real job board feeds, then fingerprints and liveness checks each one so the same posting never lands twice and dead listings drop out before they reach you.
2 · Score for fit
Every role is embedded and scored 0 to 100 against your resume. The score combines a semantic similarity signal with an LLM judgement that returns the reason, the matched skills, and the gaps.
3 · Branch on the threshold
Only roles above your fit threshold move on to tailoring. Borderline roles still get a score and a reason, but no draft, which keeps token spend tied to roles worth acting on.
4 · Tailor and track
For the strong matches it writes a tailored resume variant and an outreach draft, persists everything to your pipeline, and sends a short email digest. Applying becomes an edit, not a blank page.
This is the part I am most proud of as a product and engineering decision, not just a build. The two diagrams below encode the calls that make Job Agent safe to run for many users, free to run on a schedule, and easy to reason about one step at a time. The captions are the decisions, not descriptions.
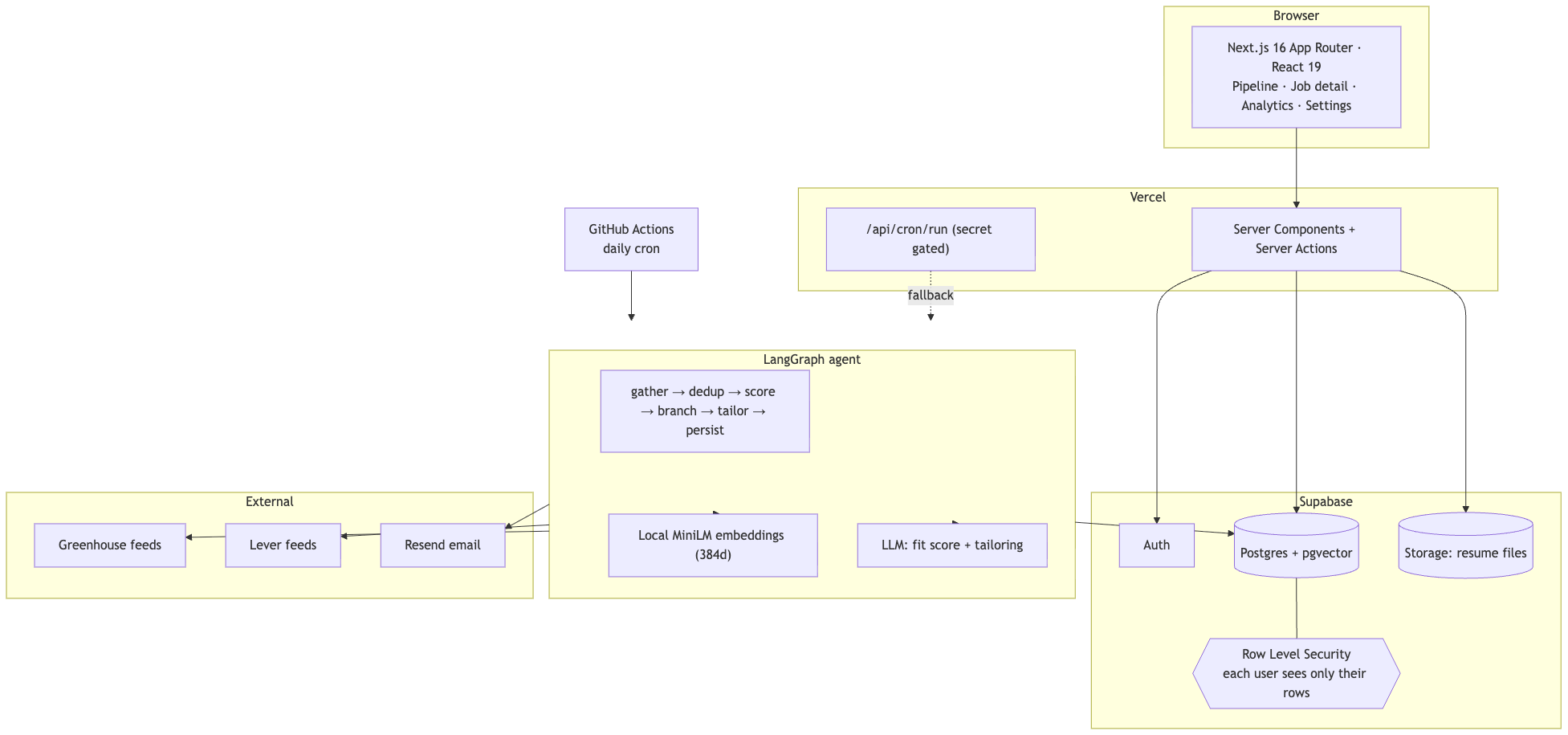

Every screen below uses a demo account with synthetic data, never a real user's job search.
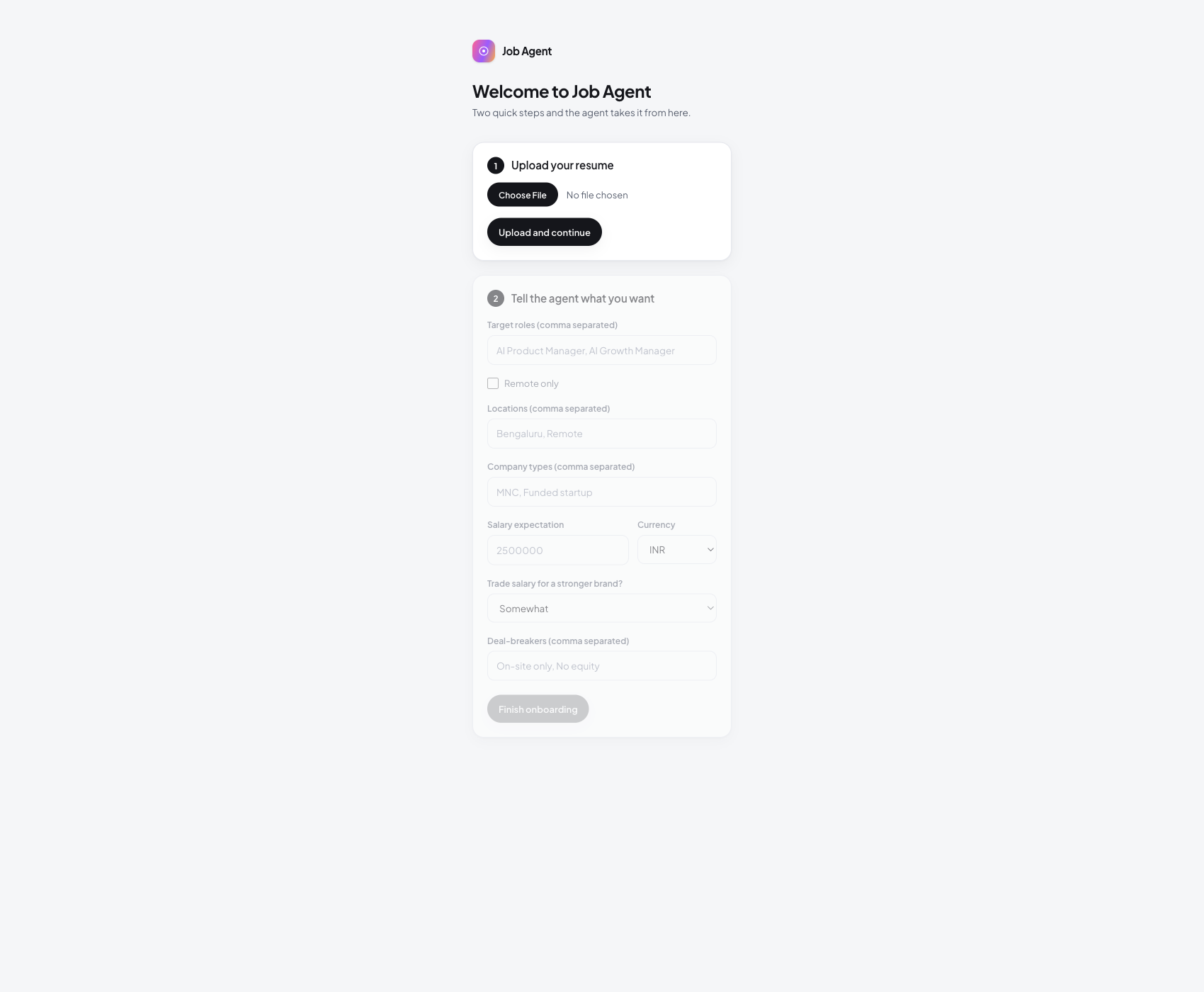
Onboard once, then step back
You upload a resume and tell the agent what you are hunting for: target roles, locations, salary, company types, deal breakers. This is the only manual setup in the whole product.
After this, the agent knows exactly what to hunt for, and the daily run takes over. Everything else on this tour is the agent's output, not work you do by hand.
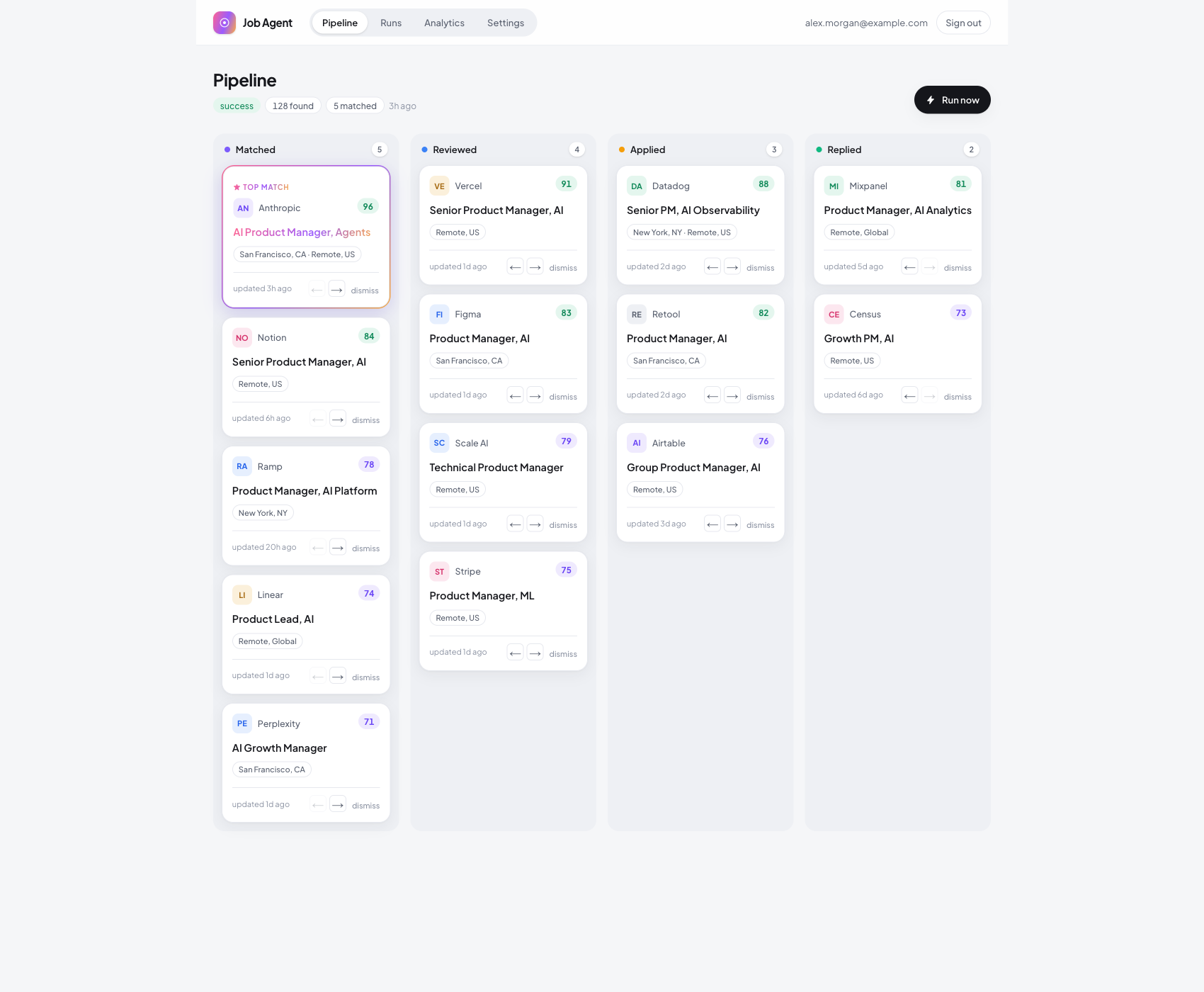
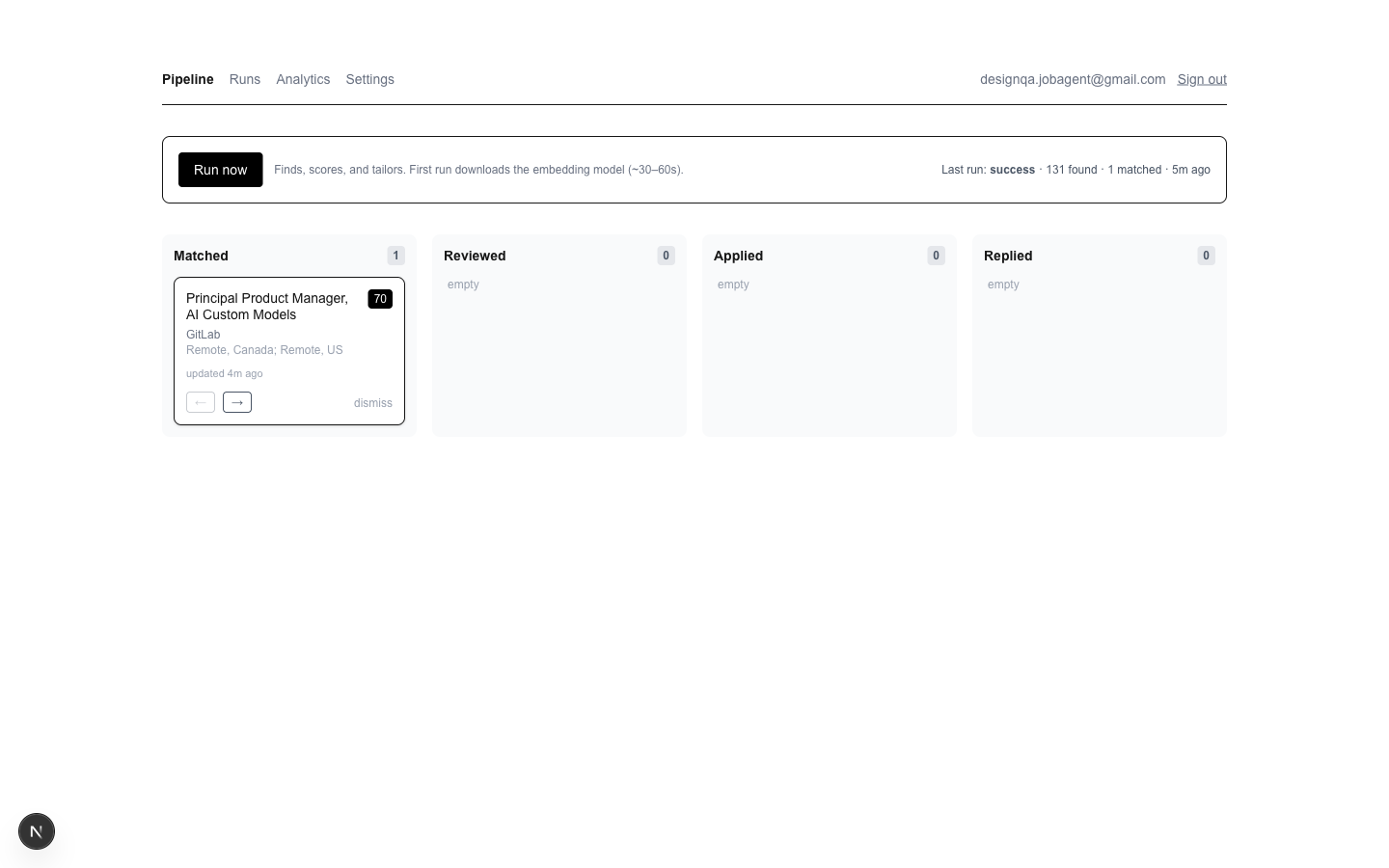
The pipeline board
Every match lands on a Kanban board and moves through Matched, Reviewed, Applied, Replied. The strongest match is promoted to a featured card so the best thing the agent found is the first thing you see.
The fit score sits where a job board would normally show salary, because fit is the number that actually matters here. You never lose track of where each role stands.
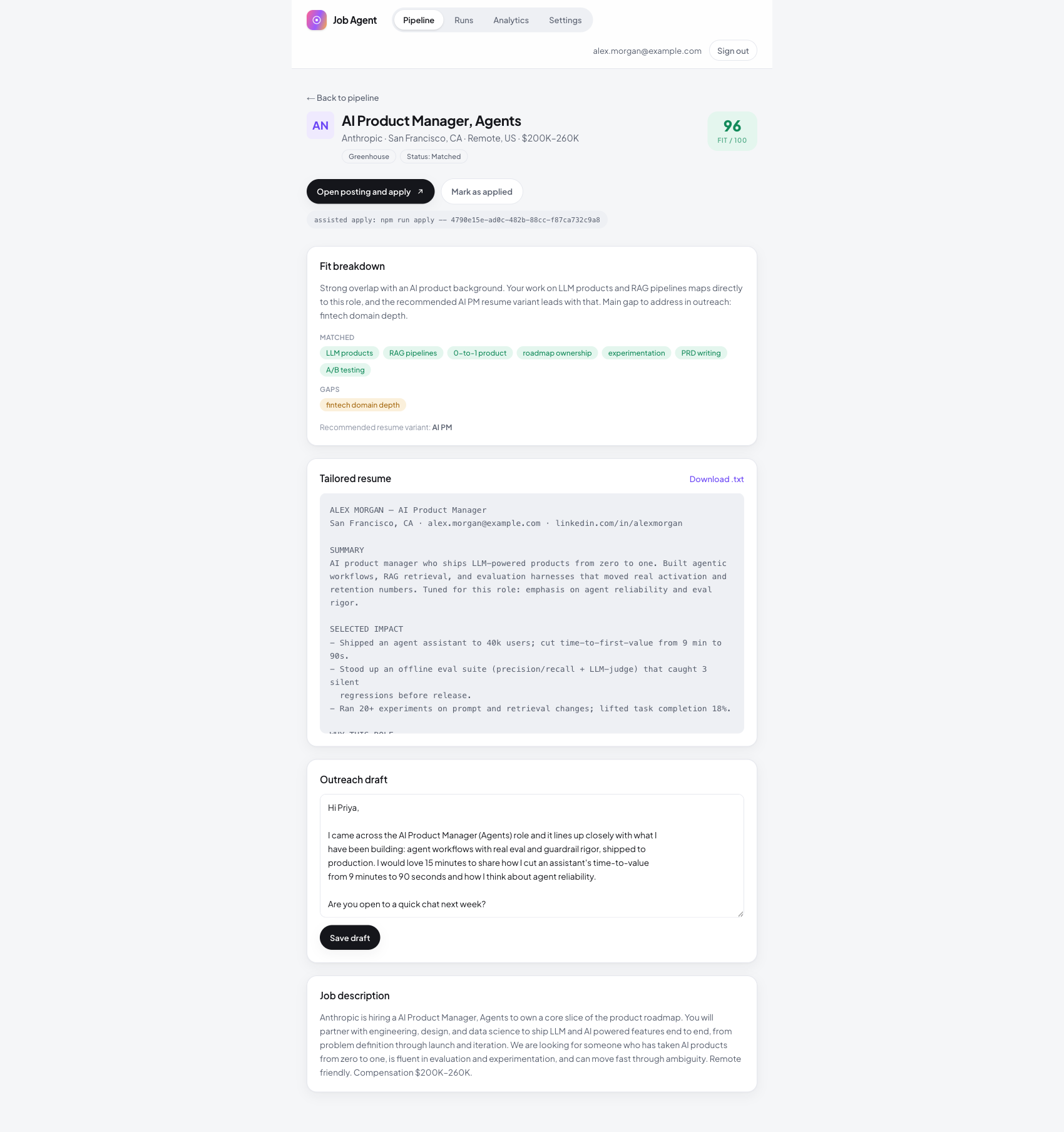
Why a role fits, and a draft ready to send
Open any role to see the fit breakdown: the reason, the matched skills, the gaps, and the recommended resume variant. So you can decide fast and prep for the gaps before you ever apply.
Below it, the agent has already written a tailored resume and an outreach draft for that role. Applying is an edit, not a blank page, so it takes minutes instead of an hour.
Know if it is working
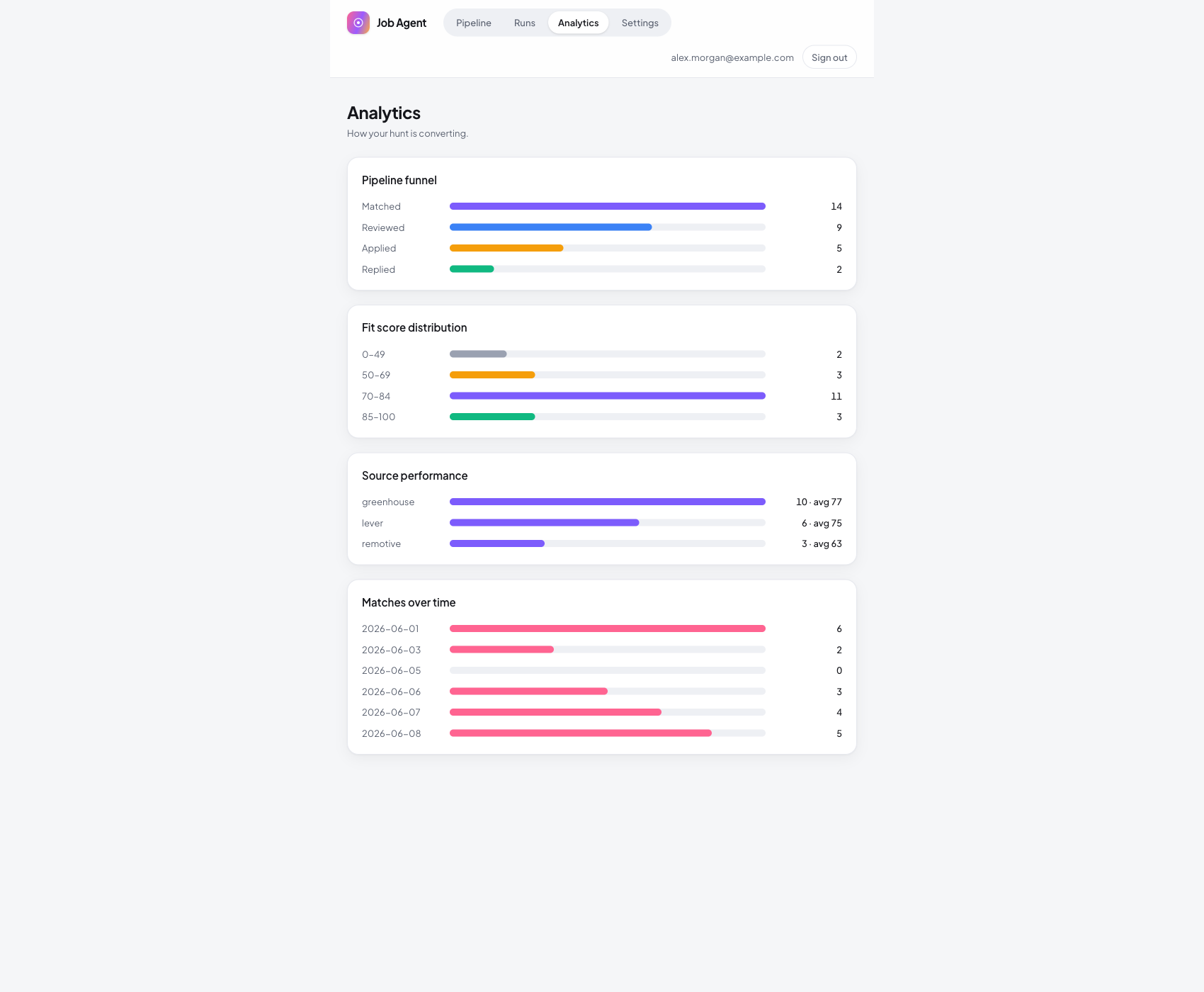
Analytics turns the hunt into numbers: the pipeline funnel, the fit score distribution, which sources produce the best matches, and matches over time.
It answers the only question that matters once the agent is running, which is whether the hunt is actually converting, without anyone pulling a report.
Every run, on the record
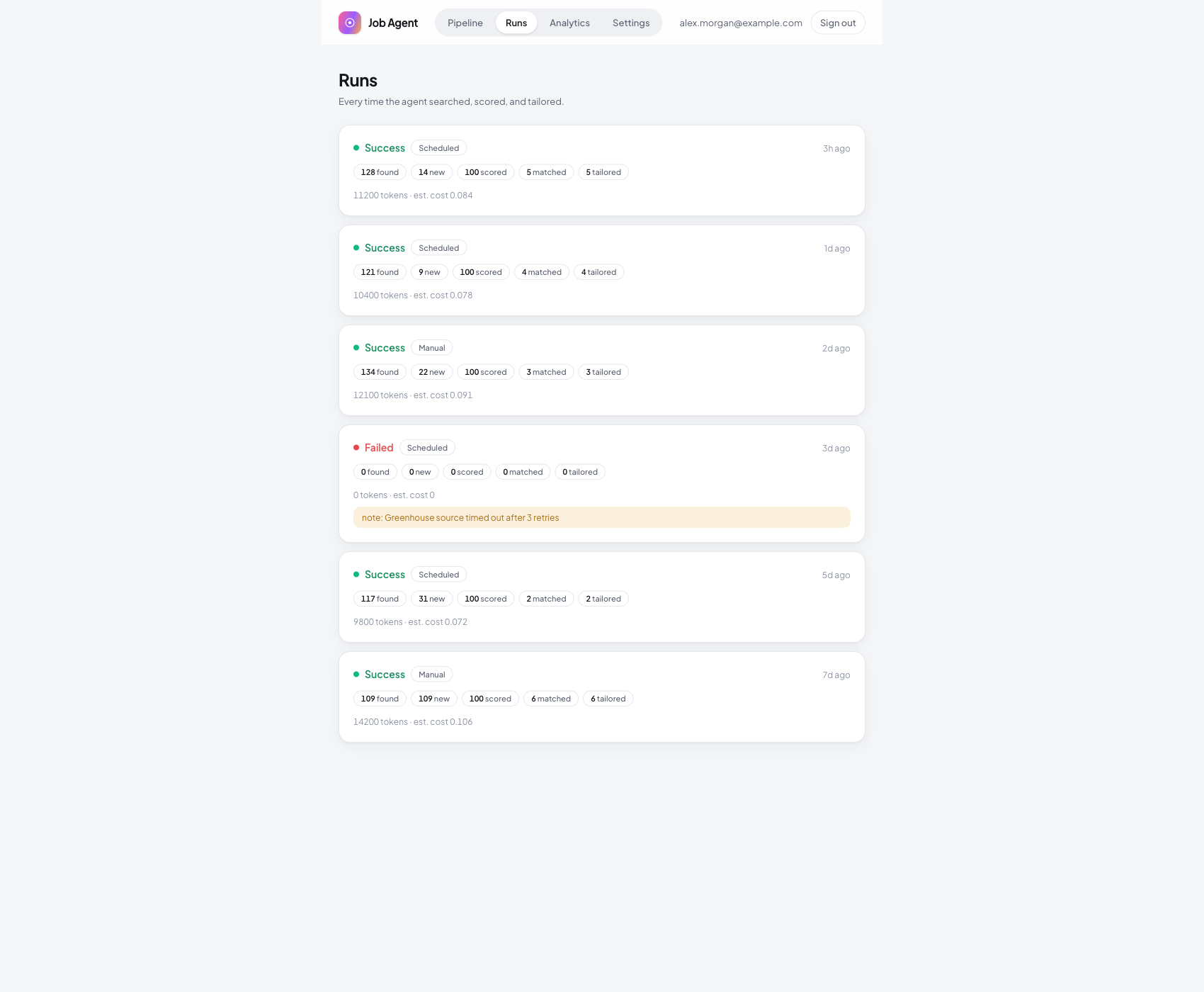
The agent runs daily on a schedule. Each run records what it found, scored, matched, and tailored, plus the token usage and cost for that run.
Failures are logged with a reason, not hidden. The work the agent does while you sleep is fully auditable the next morning.
Tune it over time
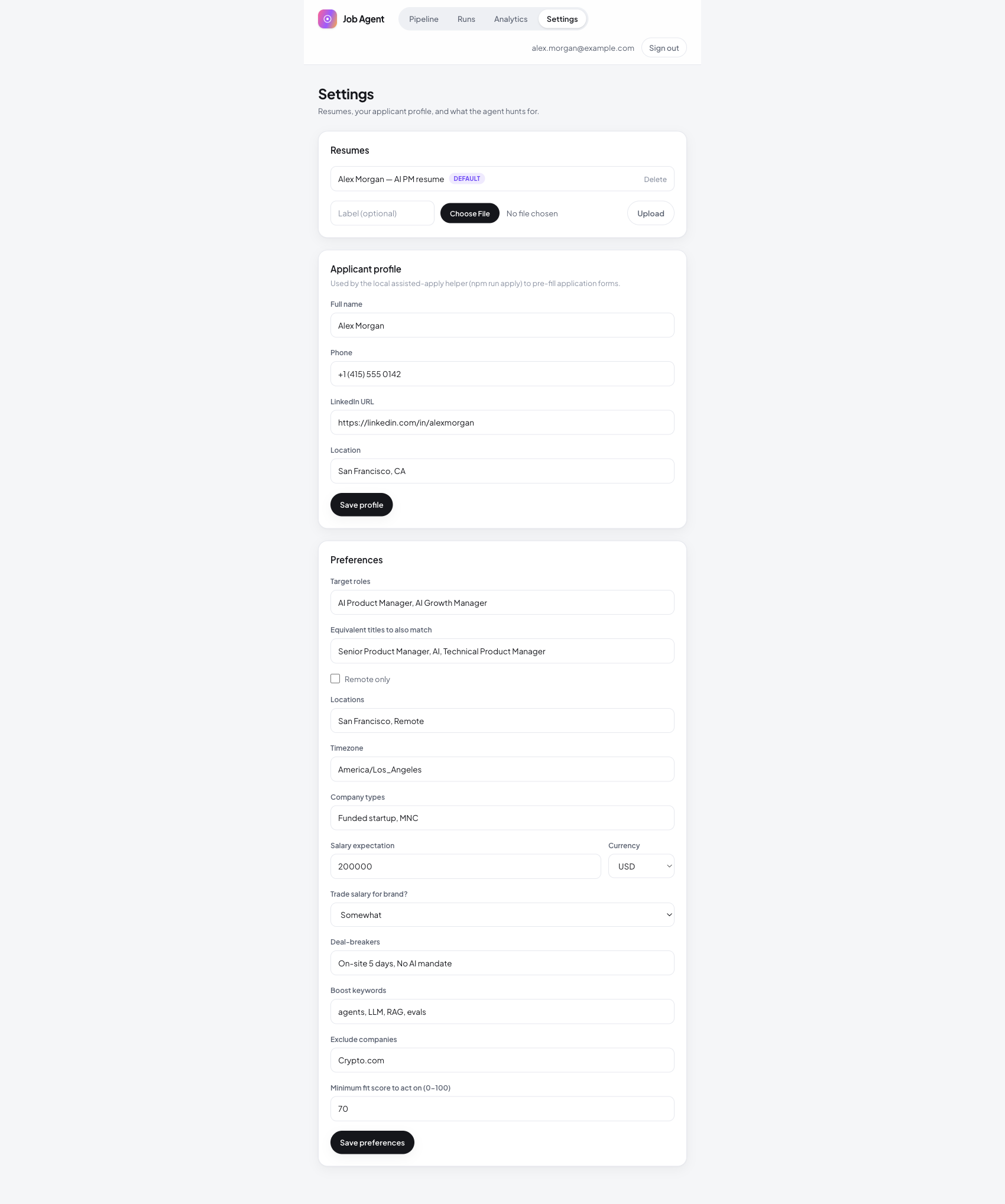
Settings is where the agent gets sharper the more you use it: manage resume variants, keep your applicant profile current, and adjust the preferences that drive matching.
The agent is not static. As you refine what you want, the scoring and the matches sharpen with you.
The first version was correct but it looked like a raw scaffold: default font, black on white, cramped, no identity. The logic worked, but nobody would trust it with their job search. So I ran a focused design pass.
I anchored the visual direction on a job board portal concept, light and airy with rounded cards and a single signature gradient reserved for the standout match, and built a real design system for it: Plus Jakarta Sans, a calm neutral canvas, soft shadows, color coded fit scores, and pill based tags and controls. The system lives as design tokens in one CSS file and a set of shared primitives, so all eight surfaces stay consistent and the whole look can be retuned from one place.
Built and shipped solo by directing AI coding tools across the full stack, the same way I ship every product I take on.
- Defined the product. Took a fuzzy, familiar problem and turned it into a multi user agent with nine clear user stories, each mapped to a real screen.
- Built the agent. Designed and built the LangGraph run: gather, dedup, score, branch, tailor, persist, notify, with local embeddings and an LLM fit judgement.
- Designed the interface. Built a real design system and applied it across all eight surfaces, taking the product from a raw scaffold to something worth trusting.
- Shipped and deployed it. Live on Vercel with auto deploy on push, a daily GitHub Actions run, Resend email digests, and 56 automated tests green.
Want the full walkthrough?
I am happy to demo Job Agent live and talk through the product decisions, the agent design, and how I scoped, built, and shipped the whole thing solo.